Full Time
position in
120 E Palmetto Park Road
Boca Raton,
FL,
33432
Job Title: Data Science Engineer
Location: Boca Raton, FL-Remote/Hybrid
About Us:
At Predictive Sales AI (PSAI), we’re redefining how technology and intelligence transform digital marketing. Our AI-powered software enables home services businesses to make smarter, faster decisions—fueling growth through automation, prediction, and precision.
Job Overview:
As a Data Science Engineer, you will design and operate the data + machine learning foundations behind PSAI’s predictive products. You will build scalable pipelines and robust warehouse/lakehouse models across CRM, marketing, product events, and external datasets — ensuring reliability, accuracy, and business continuity at scale.
This role requires:
Key Responsibilities:
Maintain clean, testable, production-ready Python codebases using:
Desired Traits:
We are looking for an individual who is organized, proactive, and detail-oriented. In this role, you will work closely with teams across the company. Here’s what we’re looking for:
Required Skills and Experience:
Why Join Us?
If you're ready to be part of an innovative, growth-oriented team, apply today!
Hours
40
We’re constantly building new products and services, and we’re looking for people who are ready to make an impact every day. Here are some of the available positions open to great candidates. Apply today!
Digital Marketing Consultant-SEO
Digital Marketing Consultant-SEO
Marketing Manager (Content, Social & Influencer Strategy)
Digital Marketing Sales Consultant
DevOps Engineer
Data Science Engineer
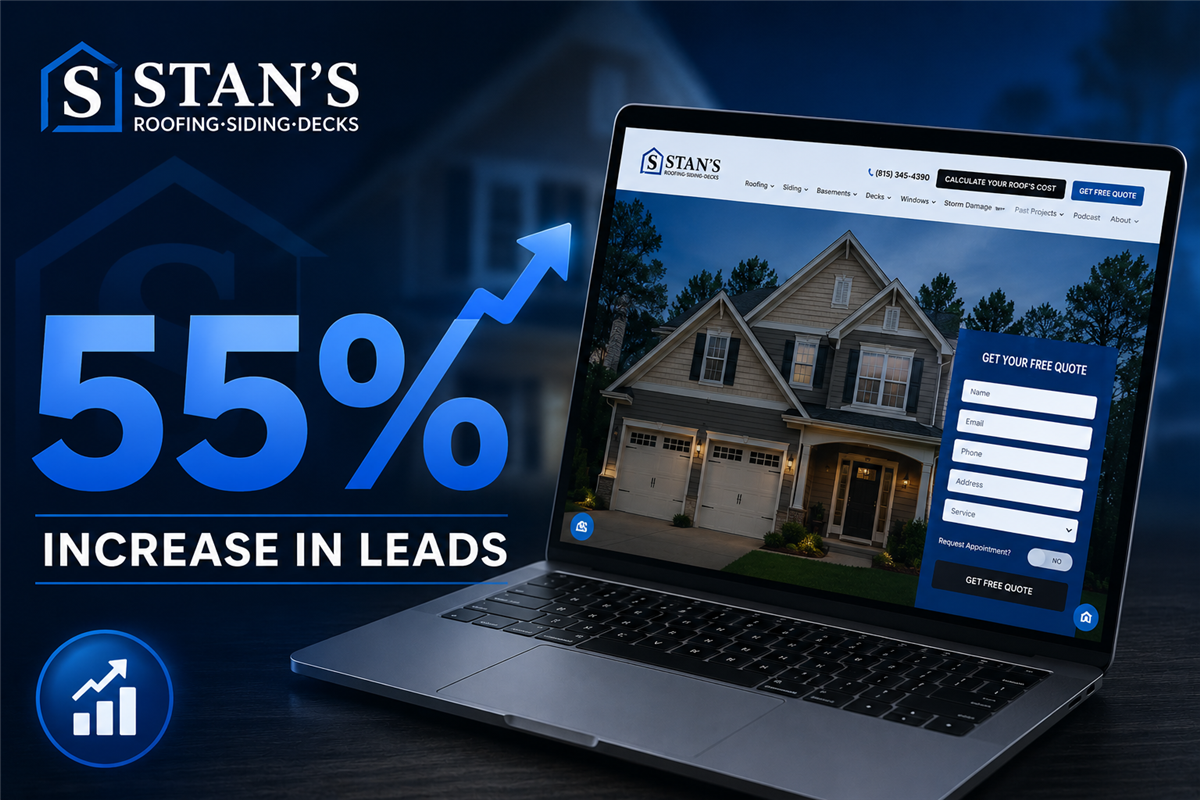
How AI Engagement & Project Showcases Helped Drive a 55% Increase in Leads
In today’s home improvement market, generating more leads isn’t just about getting more website visitors — it’s about converting the homeowners already showing interest.

The California Privacy Letters Going Around, And Why Your Platform Already Has You Covered
Over the past several months, a wave of demand letters citing the California Invasion of Privacy Act (CIPA) has been landing in the inboxes of home services businesses across the country. A small number of our own customers have received them.

Severe Weather Remains Active Across the U.S. as Damaging Wind Threat Continues to Lead the Season
After a highly active holiday week that brought severe weather to nearly every region east of the Rockies, the pattern remains active heading into July.
Let’s Get You A Free Quote
